[toc]
概要
結論:GPT3規模の衝撃が1年以内におとずれる
※本記事の主張はあくまで言語モデルのscaling lawや他言及している仮説が正しいという前提が必要です。その前提を理解した上で読み進めていただければ幸いです。
結論から言うと、
- 高い可能性で2023年内に実質的にGPT3規模の衝撃が言語モデルに1度起こる(GPT2->GPT3の性能改善への主観的な驚き=αが現状のGPT3を基準として起きる)。
- 高品質言語データ枯渇問題が解消されれば、2024年から2025年の間にPaLMやChinchilla基準から見てもGPT3規模の衝撃が起こる可能性がある。(GPT3基準から見たら1.5αの衝撃)
- 投資意欲がさらに高まれば2025年までにGPT3規模の衝撃が2回起こる可能性(GPT3基準で2α)もある。
- ->2024年から言語モデルは指示待ち人間レベルの能力を会得していく可能性が高い。
- 個人的なAGIタイムラインが2035-2040->2031-2037に3年程度前倒しになった。
上記のことが言語モデルのScaling Law(Chincilla論文)や投資意欲などの推定レポートからイメージできるのではないかと考えています。
多くの人は2023年1月現状の言語モデルを、ちょっとおしゃべりが上手になってきたのかもな、程度にしか感じていないかもしれません。しかし、ほぼ確実に1年以内にGPT3レベルの衝撃が起き(GPT2->GPT3の性能改善への主観的な驚き=αが現状のGPT3を基準として起き)、現状の言語モデルに感じている感覚を刷新するような言語モデルが登場すると思われます。(※GPT4とは限りません。)ここでGPT2->GPT3変化時の言語モデル性能への主観的な驚きをαとしましたがこちらに関しては後述の章で詳細に議論します。
また現状のGPT3を基準とすると言いましたが、PaLMやChinchillaという現状最強の言語モデルを基準としてみてもそこそこGPT3レベルの衝撃(GPT3レベルの衝撃をGPT2->GPT3の性能改善への主観的な驚きとした場合の70%くらいの衝撃)が1年以内に起こるでしょう。またChatGPTの能力は現状論文も出ておらず不確実ですが、ChatGPT基準から見ても1年以内に大きな飛躍(上記ChatGPTの言語能力をPaLMやChinchillaレベルの能力と推定)となるかもしれません。
また2024~2025年の間にPaLMやChinchilla基準から見ても正真正銘GPT3規模の衝撃が来る可能性がそこそこあると考えます。GPT3基準から見たら1.5αの衝撃、つまりGPT2->GPT3への移行時衝撃が2024-2025年までに1.5回起こると思われます。※高品質な言語データ枯渇の問題があるので、それが解消されればという条件付きです。
また更に、推定よりも投資がこのまま加速した場合3年以内に2度=2αのGPT3規模の衝撃をGPT3基準で味わうことになるでしょう。これはもはや言語モデルだけで見ても驚異的な進化であり、誰もが人類史が変わっていくかもしれない(少なくとも産業革命レベルだ)とネタではなく感じてしまう可能性が高いと思われます。
上記状況から中庸的に見れば2024年頃から本格的に指示待ち人間レベルの(何でも指示を出せば言うことを汎用的に聞いてくれる)言語モデルAIが本格的に開発されると思われます。保守的に見ても3年以内にはデータ枯渇の問題が解消されれば、開発されていくでしょう。また例えデータ枯渇の問題の解消が難しかったとしてもGPT3基準でGPT3レベルの衝撃は1年以内に起こる可能性が高いため、それを指示待ち人間レベルと呼ぶならその到来を妨げる技術的困難はないように思われます。
また様々なモーダル(言語の他にも、画像や音やアクションなど)がある中で言語を今回AIの能力を外挿する際に選んだのは、言語モデルのscaling lawが詳細に調査されているというのもありますが、言語が全てのモーダルの共通インターフェースになると考えているためです。
言語モデルの能力が上がれば必然的に他モーダルとの連携も強化されAIの包括的な世界に対する認識能力も上がると個人的に感じているため、言語に今回はフォーカスして議論したいと思います。(言語中心主義という批判も承知の上。)
また少し話はずれますが、上記推定を受けて、以前以下の記事で個人的なAGIタイムライン予測を出しておりましたが、今回の考察で3年ほど前倒しにさせていただきました。
http://futurist.cross-community.net/2022/11/05/after-10-years-sf/#LessWrong
AGI実現時期はともかく、早ければ1年以内、遅くても3年以内には指示待ち人間レベルの(指示をしたらほぼなんでも行ってくれる)言語モデルが登場し、社会全体を大きく揺さぶる技術になっていくと考えられます。
次の章から具体的な根拠やどのような計算で上記推定が導かれているのか、またスマホに言語モデルは入るのかなども次の次の章で簡単に考察できたらと思います。
大規模言語モデルの性能外挿
前の章で述べた言語モデルの能力外挿が具体的にどのように導出されているのかを以下の順で解説します。
- 言語モデルのScaling Law(Chinchilla論文)
- 主観的驚きの定量化
- 強化学習、データベース接続による性能向上
- FLOPs/ドルと投資意欲の推移
- データ量枯渇の問題
- 言語モデル能力の年代推定
言語モデルのScaling Law (Chinchilla論文)
イギリスの汎用人工知能開発組織のDeepMindは2022年3月29日に「Training Compute-Optimal Large Language Models」という論文を発表しました。
https://arxiv.org/abs/2203.15556
この論文ではScaling Lawという端的に言えば、学習させるデータ量と言語モデルのパラメータの数を増やせば性能も上がるという法則を詳細に調査しています。
ここで言っている言語モデルというのはTransformerを用いた密なモデルとなります。密なモデルというのは、全てのパラメータを使用して言語モデルが結果を吐き出すモデルのことですが、一方で入力データを振り分けてネットワークの一部のみを使うMoEと呼ばれるモデルも存在します。
普通に言語モデルと言って思いつくようなGPT3,Gopher,PaLMなどは全てこのTransformerを用いた密なモデルに該当し、今回の論文で最適なデータ量とパラメータ数で訓練された700億パラメータのChinchillaという2800億パラメータのGopherよりある意味性能の高い言語モデルもそれに該当します。
この論文では「特定のコンピューティング バジェット(FLOPs)で Transformer 言語モデルをトレーニングするための最適なモデルサイズとトークン数」を調査し公式化しており、また「結果としてどの程度性能(クロスエントロピー)が減少するか」という式も経験則的に公式化しています。
つまり、この論文を使えばある特定の計算資源(演算回数FLOPs ※FLOPSは1秒あたりの浮動小数点演算回数、この場合小文字のsのため注意)が与えられた時の最適なパラメータ数と学習データ数を割り出せて、さらにその性能(クロスエントロピー)まで計算できてしまうので、めちゃくちゃ言語モデルの性能予測にうってつけというわけです。
以下に数式を載せます。
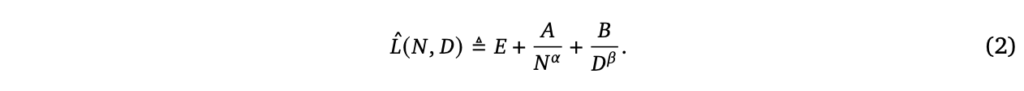
上記式(2)の左辺が損失関数=クロスエントロピー関数となります。小さければ小さいほど性能は良くなります。
右辺のEが自然文のエントロピーと解釈できるもので、端的に言えば人間の書く文章の持つ確率分布のエントロピーとなります。またNがパラメータの数で、Dがデータセットのサイズを表しています。
ここで二つのアプローチ(学習トークン数を変化させるもしくはパラメータ数を変化させる)から上記式の定数が経験的に求められています。
E=1.69,A=406.4,B=410.7,α=0.34,β=0.28,a=0.46,b=0.54(このa,bは後ででてくる式(4)で使います)
つまり、この損失関数を最小化するためにはNとDをとにかく大きくして最終的にクロスエントロピーを人間の書く文章のエントロピーに漸近させていけば良いということになります。以下イメージです。
クロスエントロピー=人間の書く文章のエントロピー+相対エントロピー/KL divergence(NとかDとかの項)
イメージとしては最終的には人間の書く文章のような確率分布にできる限り大規模言語モデルのそれを寄せていきたいわけです。そのためには機械の出力する文章の確率分布と人間の出力する文章の確率分布の差=相対エントロピー/KL divergenceをゼロにしていけばいいわけです。
そうすれば機械の出力する文章の確率分布であるクロスエントロピーが人間の書く文章のエントロピーに一致します。つまりディープラーニングにおけるクロスエントロピー最小化は、ある目標とする確率分布からの離れ具合=相対エントロピーをゼロにしていくということを意味すると考えるとわかりやすいでしょう。(以下参考にさせて頂いた動画)
少し話はずれましたが、つまり式(2)に経験的に求まった各種パラメータを代入すれば性能=クロスエントロピーの値が求まります。
しかし、これだけではある特定の計算バジェットFLOPsが与えられた時の最適なパラメータ数とデータセットのサイズがわかりませんが、以下のようにそれも公式として導出されています。
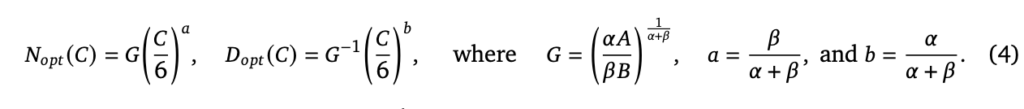
ここにも先ほど挙げた実験でもとまった各種パラメータの値を代入すれば、最適なパラメータ数=Noptと最適なデータサンプル数=Dopt(単位token)がC(計算バジェット、FLOPs)を条件として計算できます。
主観的驚きの定量化
前節でクロスエントロピーの導出はある特定の計算資源が与えられたらできるようになりました。
しかし、クロスエントロピーの値がなんとかです!と言われてもパッとそれがどれだけすごいのかイメージがつきにくいと思われます。
そこで以下の方の、ある種の主観的な驚きの定量化手法として使用している方法を参考に用いることでそのわかりにくさを改善したいと思います。
この方も私と同じようにChinchilla論文からクロスエントロピーの値を求めて、次のGPT4はどの程度の性能になるかを定量的に予測するスレッドを展開しておられます。(GPT4が密なモデルになるかは不明で、また、若干データ量の仮説が楽観的なところを除けば相当良いスレッドになっています。というかこの方のツイートアイディアがなければこの記事の半分は書けてない気がします。)
具体的にどう主観的な驚きを定量化しているかというと(この方が主観的な驚きという言葉を使っているわけではなく、私の解釈です)、前節で出てきた相対エントロピー/KL divergenceのマイナスのlog2を用いています。
これはつまり相対エントロピー(人間の地の文からどれだけ離れているかという指標)が例えばGPT2->GPT3で1/10になったとし、その時と同じレベルの主観的な驚きがくるためには、さらにそこから相対エントロピーを1/10にする必要があるはずだという仮定となります。マイナスをつけているのは単に符号をプラスにしたいからで、対数の底が2なのも特に意味はなくどんな値でも構いません。
人間の主観的感覚は刺激に対して線形に伸びているわけではなく、ウェーバーフィヒナの法則のように対数的に分布しているという話があるので妥当な仮定なのではないかと個人的には思っています。
データベース接続、強化学習による性能向上
言語モデルの性能を上げるための手法は学習時のデータセットの大きさやパラメータ数の増加に留まりません。
例えば以下のように去年DeepMindはRetroというデータベースに言語モデルを接続させるアイディアで75億パラメータのRetroがPileデータセット上で1750億パラメータのGPT3と同等性能を叩き出しています。25倍のパラメータ数がある言語モデルと同等性能になるというのには驚きです。
https://jalammar.github.io/illustrated-retrieval-transformer/
(※参考 : 現状の言語モデルはコンテキスト長が8000tokenほどしかないという問題、つまり8000token以上のことを文脈=プロンプトとして扱えないため、短期記憶もその程度になるという問題もひとまずデータベース接続で解決する可能性があると思います。https://twitter.com/bioshok3/status/1605083401567866880?s=20&t=d6dZo_wEuB78MWd17brqWw)
またOpenAIはInstructGPTと呼ばれる13億パラメータのPPO-ptx(およびPPO)が1,750億パラメータのGPT3よりもはるかに人間好みの文を出力し、他NLPタスクについてもパラメータ低下の影響は最小限となる結果を今年の1月に発表しています。
https://openai.com/blog/instruction-following/
他Webに接続することで7億6000万パラメータでTruthfulQAにおける真実性、有用性指標でどちらもGPT3を上回るという結果も昨年OpenAIからWebGPTという形で発表されています。
https://openai.com/blog/webgpt/
他にも思考の連鎖(CoT)、
アルゴリズムプロンプト(https://twitter.com/oh_that_hat/status/1593337982144110593?s=20&t=8iya1HpNdddwAXyeed4kjw)、
形式的推論AIのLAMBAD(https://twitter.com/bioshok3/status/1608656678068842497?s=20&t=8iya1HpNdddwAXyeed4kjw)、
多数決(自己一貫性)、微調整データセットの自己生成による強化(https://twitter.com/_akhaliq/status/1584343908112207872?s=20&t=7GTmk4z54wnFPdpNkZkfiw)
真偽構造の強化(https://twitter.com/bioshok3/status/1601097888142045184?s=20&t=7GTmk4z54wnFPdpNkZkfiw)
外部知識活用(プログラム呼び出し、物理シミュレーションhttps://twitter.com/bioshok3/status/1580477735323209728?s=20&t=7GTmk4z54wnFPdpNkZkfiw)
など挙げればきりがないほど言語モデルの強化手法はデータセットやパラメータ数の増加以外にも無数に提案されています。
そのため、Scaling Lawの外挿推定では上記のような状況を鑑みて、ある言語モデルが学習された瞬間に、そのモデルと学習データ数は同じだがパラメータ数を1倍(保守的な予測)、10倍(中庸的な予測)、100倍(積極的な予測)にしたものと同じ性能の言語モデルが上記手法を組み合わせて出てくると仮定します。
ちなみにChatGPTの言語能力がどれくらいか?というところが気になります。様々な微調整や強化学習手法を用いてGPT3レベルの言語モデルから派生しており、まだ論文も出ていないため、一概に能力を推定することはできないのですが、上記の議論でいうGPT3の学習データ数は同じでパラメータ数が100倍のモデルと同じと仮定し暫定的に後の性能計算で考えてみたいと思います。
FLOPs/1ドルと投資意欲の推定
段々と言語モデルの能力を推定するためのピースが揃ってきましたが、そもそもどのように計算資源(FLOPs)を決めるのでしょうか?その際に参考になるのが以前の記事でも紹介した以下のAGI(正確にはTAI、変革的AI)実現時期推定レポートとなります。
このレポートのgoogledriveの4/4の章では、ある未来の時点で1ドルあたりどの程度の演算量を買えるかの推定と学習に投じることのできる投資意欲がどのように増えていくかを推定しています。
以下その二つのグラフを貼り付けます。詳細なデータは以下。
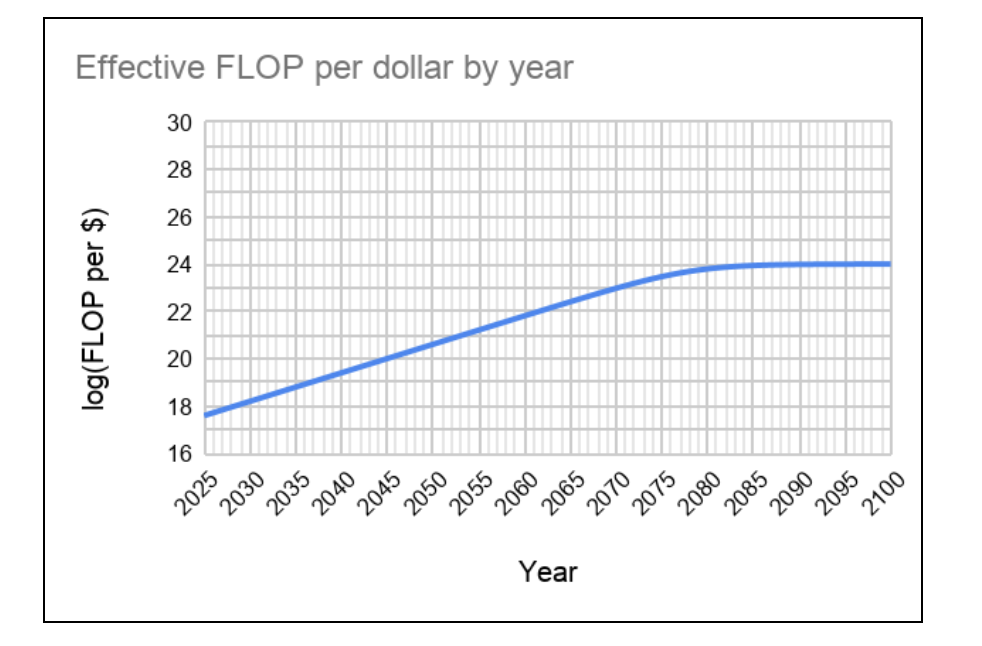
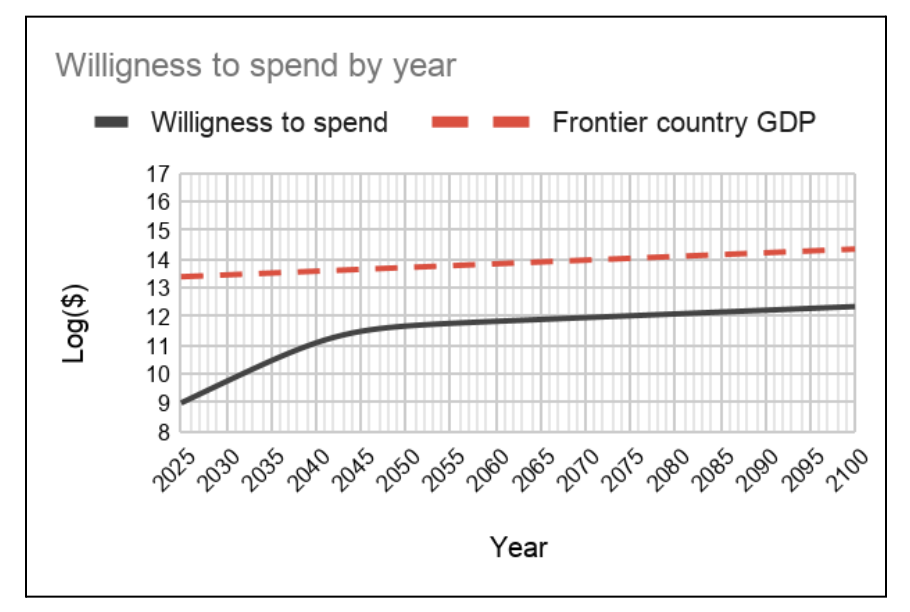
この二つのデータを掛け合わせれば20xx年にどのくらいの演算量(FLOPs)が学習に投じられるかを計算できます。しかし、この二つのデータは2020年に書かれたレポートのデータなので、現状から見るとやや保守的な推定だと思われます(著者も認めています)。
実際、上記レポート著者は2020年時点におけるFLOPs/ドルの値を「10倍保守的に見ていた」と2022年8月に以下で述べています(純粋なハードウェア性能2.5倍*大企業割引2.5倍*使用率改善1.5倍=9.37倍)。しかし成長率=レートは変わらないと述べています。そのため単純に全ての桁を1桁上げることで対応することにします。
また、このレポートでは2040年頃までに半導体の純粋な演算速度の改善を3倍程度と相当保守的に見積もっていますが、ムーアの法則は2036年頃まで2.5年に一度の倍加速度で進行する可能性が示唆されているため、上記予測の2040年頃の演算量を1桁増やしても問題はないと考えられます。
そして、2025年時点で10^9ドル=大体1500億円程度の投資がなされるだろうという予測は、既に2024年に10億ドルの収益をOpenAIは見込んでいるとされ、その企業価値は現時点(2022/12)で数百億ドルにものぼるという話もあり、1500億円程度の投資はMicrosoftがバックにいることも考慮に入れると2024年中に起こっても不思議ではないかなという感覚値はあります。しかし、ここは2025年までに10億ドルが投資されると想定しておきましょう。
https://www.euronews.com/next/2022/12/15/openai-chatgpt
上記推定を全て鑑みて以下のようなタイムラインで演算量と投資資金は推移すると考えてみます。
10^25FLOPs(2023)1000万ドル
10^26FLOPs(2024)1億ドル
4*10^27FLOPs(2025) 10億ドル
7*10^27FLOPs (2026) 13億ドル
10^28FLOPs(2027)17億ドル
2*10^28FLOPs(2028) 23億ドル
3.6*10^28FLOPs(2029) 30億ドル
6*10^28FLOPs(2030) 40億ドル
10^29FLOPs(2031) 50億ドル
2*10^29FLOPs(2032)67億ドル
3*10^29FLOPs(2033) 90億ドル
10^30FLOPs(2035) 150億ドル
10^31FLOPs(2037) 257億ドル
10^32FLOPs(2040) 550億ドル
高品質言語データ枯渇の問題
さてこれで言語モデルの能力推定に入っていけると思ったらまだ壁が立ちはだかります。そもそも計算資源の問題はいいとして(GPUを増設すれば良いため)、データ量はどこまでスケールできるのかという疑問が湧いてきます。
以下の論文は言語について高品質(書籍、論文、ニュースサイト、Wikipediaなど)と低品質(他SNS,WEBサイトなど)データで分類し、データ量が現状どの程度あって、いつまでにデータを使い果たしそうかを推定しています。
https://arxiv.org/abs/2211.04325
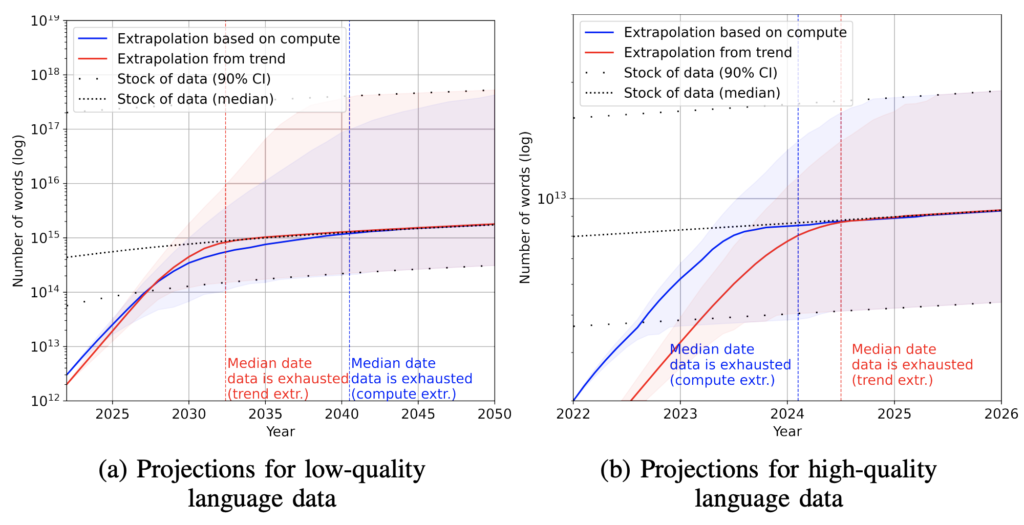
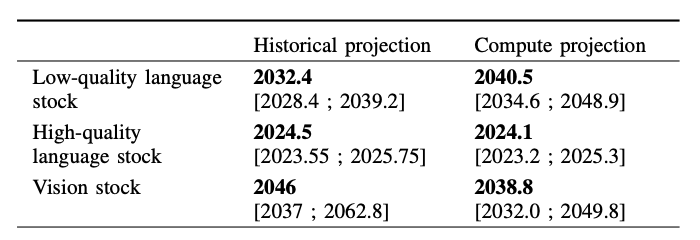
左が低品質データで右側が高品質データのグラフとなっています。
およそ2024年の1月までにCompute projection(TAI投資意欲の推定を使った試算)で高品質データが枯渇すると予測されています。しかしこの予測は2020年時点におけるTAI投資意欲の推定予測を用いているためやや保守的な結果となっていると考えられます。恐らく2023年の早いうちに高品質データの全てを使い果たしてしまう可能性があると考えられます。
ちなみに高品質データは論文によると9*10^12token現状存在するだろうと推定されており、また低品質データを合わせると7.41*10^14tokenとなっています。
基本的に高品質データを選んでランキングし学習させた方が精度が良くなるというような下記論文が出ているため、できる限り質のいい文章を選んで学習した方がいいのは恐らくそうなのですが、低品質データを増やすことでどこまでスケーリングするかというところはまだ未知数な気がします。
https://openreview.net/forum?id=UmvSlP-PyV
しかし個人的には高品質データが枯渇する2023年までに低品質データから高品質データを抜き取る手法やデータの拡張手法(言語モデル自身が高品質なデータを多様に生成し続ける)が編み出されることで上記ボトルネックは解消されるのではないかと考えています。
実際、思考の連鎖の例をPaLM540Bが生成しPaLM540B自体の能力を上げています。しかも質問文さえも自分で生成する実験もしてて、それをCoTで答えたもので微調整して精度が向上しています。
実際Meta AIがわずか15のプロンプトから24万の微調整用データを拡張し、言語モデルの精度を上げる成果を出しています。
これは一例でこのような言語モデル自身に微調整用または評価用のデータを拡張させるという論文は最近増えていっているように感じます。その延長線上で事前学習用のデータそのものの拡張手法も増えていくのではないでしょうか。
また、ある程度質のいい大規模言語モデルに強化学習を繰り返すことで低品質データから高品質データを抽出してもらう/さらに良いデータを作ってもらうように促すことも可能だと個人的には考えており、その方向でいけばデータの不足の問題は解決の兆しがあるのではないかと思っています。(今回の記事では言語モデルのみにフォーカスしていますが、今後マルチモーダルのscaling lawのようなものが出てきたらそもそも言語側でデータの不足に悩む必要もなくなるかもしません。)
言語モデル能力の年代推定
長くなりましたが、ここまできてやっと言語モデルの能力推定をする材料が揃いました。
結果から以下に貼らせていただきます。
ここでα=GPT3の相対エントロピーのlogのマイナスからGPT2のそれを引いた値=1.436です。つまりGPT2からGPT3への驚きの値と解釈できます。またChatGPTについてはGPT3の100倍のパラメータ数の能力と仮定しています。(不確実性が大きい部分)
以下のような配置で書かせていただいています。
年代、相対エントロピーのマイナスのlog(底は2)、計算バジェット、相対エントロピー導出のために使用するパラメータ数(実際のパラメータ数とは限らない)やトークン数、投資額
・2019 0.243(GPT2 15億パラメータ 20*10^9 40GB)
・2020 1.679(GPT3 1750億パラメータ 300*10^9token )
・2022 1.922(ChatGPT(仮) 17.5兆パラメータ 300*10^9token)
・2022 2.019(Chinchilla 700億パラメータ 1.4*10^12token)
・2022 2.096 2.56*10^24FLOPs (PaLM 5400億パラメータ 7.8*10^11token) 数100万ドル
ーーーーここまでは2023/1/1時点までの典型的な大規模言語モデル、ここから外挿
・2023 2.677 10^25FLOPs(1800億パラメータ 9*10^12token) 1000万ドル
3.0 (1.8兆パラメータ 9*10^12token)
3.19≒GPT2+2α(18兆パラメータ 9*10^12token)
ーーーー高品質データ枯渇 データ拡張か低品質データから抽出
・2024 3.181 10^26FLOPs(5400億パラメータ 3*10^13token) 1億ドル
3.512 (5.4兆パラメータ 3*10^13token)
3.694≒GPT2+2.5α (54兆パラメータ 3*10^13token)
・2025 3.996 4*10^27FLOPs (3兆パラメータ 2.3*10^14token) 10億ドル
4.323 (30兆パラメータ 2.3*10^14token)
4.50 (300兆パラメータ 2.3*10^14token)
・2026 4.12 7*10^27FLOPs(3.8兆パラメータ 3*10^14token) 13億ドル
4.446 (38兆パラメータ 3*10^14token)
4.624 (380兆パラメータ 3*10^14token)
・2027 4.198 10^28FLOPs (4.5兆パラメータ 3.7*10^14token) 17億ドル
4.523≒GPT2+3α(45兆パラメータ 3.7*10^14token)
4.70 (450兆パラメータ 3.7*10^14token)
・2029 4.481 3.6*10^28FLOPs(8兆パラメータ 7.4*10^14token) 30億ドル
4.80 (80兆パラメータ 7.4*10^14token)
4.983 (800兆パラメータ 7.4*10^14token)
ーーーー低品質データ2022年時点のデータ量分枯渇 データ拡張などの必要あり
・2031 4.707 10^29FLOPs (10兆パラメータ、10^15token) 50億ドル
5.03 ≒GPT2+3.3α(100兆パラメータ、10^15token)
5.207 (1京パラメータ、10^15token)
・2032 4.860 2*10^29FLOPs(17兆パラメータ 1.9*10^15token)
5.183 (170兆パラメータ 1.9*10^15token)
5.358 (1.7京パラメータ 1.9*10^15token)
・2033 4.95 3*10^29FLOPs (21兆パラメータ、2.3*10^15token) 90億ドル
5.272 (210兆パラメータ、2.3*10^15token)
5.447 (2.1京パラメータ、2.3*10^15token)
・2035 5.257 10^30FLOPs(40兆パラメータ 5*10^15toke) 5.58 150億ドル
5.58 (400兆パラメータ 5*10^15token)
5.754 (4京パラメータ 5*10^15token)
・2037 5.70 10^31FLOPs (100兆パラメータ 1.5*10^16token) 257億ドル
6.02≒GPT2+4α (1京パラメータ 1.5*10^16token)
6.199 (10京パラメータ 1.5*10^16token)
・2040 6.233 10^32FLOPs(300兆パラメータ 5.4*10^16token) 550億ドル
6.548 (3京パラメータ 5.4*10^16token)
6.719 (30京パラメータ 5.4*10^16token)
また以下図1に計算リソースFLOPSとそれに対応する驚きの値を2027年までグラフにプロットします。ここで使用しているのは中庸予測(パラメータ数を10倍にした時の驚きの値を使用)となっています。ここで中庸予測での2023,2024,2025年に開発される言語モデルをそれぞれ、2023X,2024X,2025Xと置いています。
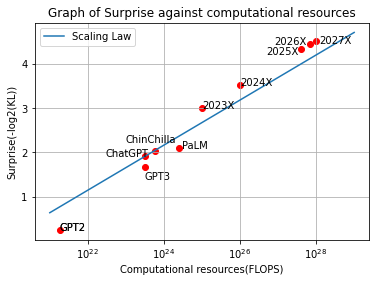
2023年から2024年にかけてGPT3レベルの衝撃(GPT2+2α=3.115)が一度起こる可能性が高くなっています。2023年の中庸的な予測であっても、すでに3.0となっており、積極的には3.19でどちらにせよ、2023年度中に実質GPT3レベルの衝撃を与える言語モデルが出現する可能性が高いと思われます。
そして不確実性は高いにせよ上記推定よりChatGPTの性能はおおよそChinchillaやPaLM程度と想定できる可能性があります。ゆえにGPT2->GPT3ほどの衝撃ではないにせよChatGPTを基準に考えても、2.0付近から3.0を超える衝撃なので、GPT3の衝撃に近いもの(αの70%)が年内に起こる可能性があるかもしれません。PaLMやChinchilla基準から見たらほぼ確実にGPT3の衝撃にそこそこ近い驚きが年内に出てくると言っていいでしょう。
また、 GPT3レベルの衝撃が1.5回(GPT2+2.5α=3.833)起こるだろう未来は2024-2025年の間の可能性が高いでしょう。このレベルになればPaLMやChinchillaやもしかしたらChatGPTの基準からしてさえ正真正銘のGPT3レベルの衝撃となる可能性があります。
そしてGPT3レベルの衝撃は2回(GPT2+3α=4.551)中庸的に見ても2027年までに起こる可能性が高くなっています。
また上記結果は投資意欲が2020年段階のレポートの推定通りにいったらという話なので、投資意欲が加速すればもっとGPT3規模の衝撃が例えば2回来るタイムラインは2025年頃まで早まってしまうかもしれません。
17億ドルという額を出せばデータ量の問題さえ解決していればGPT2+3α(GPT3規模の衝撃が2回)の言語モデルを訓練可能で、OpenAIなどの評価額は200億ドルに達しているということでありえない額ではないと思われます。
少し話はずれますが、個人的にAGIレベルの人工知能は3.3αから4αの間に出現するのではないかと主観的に感じています。つまり、GPT3レベルの衝撃があと2022年から見て2回よりちょっと多めから3回起こるうちにAGIレベルの人工知能が出てくるのではないかという感覚です。(AGIの定義はざっくり人間のこなせるタスクはなんでもこなせて世界に好奇心や能動性ももち、ポテンシャルとしてハードやソフトの自己改善も可能といったニュアンスです。)
上記結果からは2031年から2037年あたりがGPT2+3.3α/4αとなる年代となります。(以前ブログでお伝えした2035-2040年という個人的なAGIタイムラインより3年程度早まっているイメージです。)
スマホに言語モデルはのるか(参考)
前の章で述べた言語モデルの能力推定は大規模言語モデルにフォーカスしてきましたが、実際にユーザーがローカルで使えるレベルの言語モデルはどの程度進化をするのでしょうか。
スマホに乗せるためのボトルネックとなっているのは演算速度ではなく現状メモリの問題が大きいと考えられます。
上記資料によると言語モデルのパラメータあたり2FLOPsの演算が1tokenあたりの計算で求められると言うことです。100億パラメータとしても2*10^10FLOPs、100tokenを1秒で処理したい場合でも2*10^12FLOPSあれば足りるのではないでしょうか。現状のiPhone14 Proは10^13FLOPSのチップを搭載しているので現状の最新のスマホなら余裕を持って推論計算が言語モデルが100億パラメータの場合できそうです。
https://ja.wikipedia.org/wiki/Apple_A16
しかし現状iPhone14 Proのメモリは6GBのためGPT3規模の言語モデルを載せようとすると175GB最低パラメータ保存だけで必要になり全く足りません。(現状最新のGPUでもVRAMは数十GBなので1つのGPUでは推論さえできません。)
そこでiPhone14Proで6GBのメモリなのでその半分でどの程度までの言語モデルを作れるか少し見てみました。
- 1.24 (30億パラメータ 10^12token)
- 1.783≒GPT3レベル (300億パラメータ 10^12token)
- 2.12 ≒ PaLMレベル (3000億パラメータ 10^12token)
「ローカルに」3GBで例えば強化学習やデータベース接続などを駆使したらPaLMレベルの言語モデルが載る可能性があります。
2022年には10^12tokenで学習してるのだから、2024年には普及する可能性はありそうです。
しかもこれはローカルの話で、クラウドAPI利用も加味したら2023年の可能性もあります。
- 1.55 (30億パラメータ 9*10^12token)
- 2.264 PaLMレベル (300億パラメータ 9*10^12token)
- 2.75 (3000億パラメータ 9*10^12token)
現状の高品質データを30億パラメータに全部学習させたらどうなるか?というと2022年時点では存在しないレベルの言語モデルの能力(2.75)がスマホに乗ってしまう可能性があります。しかし流石に9*10^12tokenを学習させる組織はまだ現れないでしょうから、2024(クラウドAPI利用)~2025(ローカル)というようなイメージかもしれません。
- 1.951 (100億パラメータ 9*10^12token)
- 2.549 (1000億パラメータ 9*10^12token)
- 2.936 (1兆パラメータ 9*10^12token)
ちなみに10GB~のメモリを使用できる場合は上記のような結果となります。
2024(クラウドAPI利用)2025ー(ローカル)?
ーー
上記議論はローカルに言語モデルを乗せるとしたら?という話にフォーカスしているため、クラウドAPI利用で予想以上に早くもっと能力の高い言語モデルを利用できてしまう可能性はあります。
まとめ
- 高い可能性で2023年内に実質的にGPT3規模の衝撃が言語モデルに1度起こる。
- 2024年から2025年の間にPaLM基準から見てもGPT3規模の衝撃が起こる可能性が高い。
- 投資意欲がさらに高まれば2025年までにGPT3規模の衝撃が2回起こる可能性もある。
- ->2024年から言語モデルは指示待ち人間レベルの能力を会得していく可能性が高い。
- 個人的なAGIタイムラインが2035-2040->2031-2037に前倒しになった。
上記のようにまとめさせていただきましたが、ボトルネックになりそうなのはやはりデータ量です。いくら投資意欲が加速してもデータ量が追いつかなければ学習を行わせることができません。しかし、投資意欲や計算資源はあるため、一度データ量の問題がデータ拡張手法や、低品質データからの抽出手法など開発されてしまえば瞬く間に性能を向上させ始めると思われます。
少なくとも3年以内にはデータ量の問題は解決する可能性が高いと個人的には思っているので、高品質データの枯渇まで1回はGPT3規模の衝撃は起こり、保守的には3年後までマイナーアップデートが続き、そこからまた発展するという流れになるのではないでしょうか。またGPT3規模の衝撃が一度起こるだけでも相当な能力、指示待ち人間レベルと形容してもいい能力を言語モデルは会得すると考えられます(PaLMやChinchilla基準から見てもGPT3の衝撃の70%程度、不確実ですがChatGPTから見ても)。よって2023年内に衝撃が一度起きれば、2024年からは言語モデルに限定しても指示待ち人間レベルの知性が誕生していることでしょう。
またデータ量のボトルネックが解決されればGPT3規模の衝撃が1回(2023年内),1.5回(2024-2025),2回(2027年まで)に起こることが推定され、投資意欲が加速すればそれらすべてが3年以内に起こる可能性も否定できません。1回でも衝撃的だと推定されるのに、それが2回も3年以内に起こったら確実に世界全体の経済構造をラディカルに変える技術になることはほぼ明白でしょう。
さらに上記は言語モデルの能力向上のみを考慮に入れた議論でマルチモーダルの話は一切入っていません。また、アルゴリズムの改善も考慮に入れていません。そのため現状の言語モデルの技術のみを持ってしても上記のような結論が出てきてしまうというところにAIの性能進化のポテンシャルが見出せるのではないでしょうか。
少なくとも数年以内の指示待ち人間レベルと前の記事でも言った話は早く実現することはあれど3年後も実現していないということは上記議論から考えにくいと思われます。そのため少なくとも指示待ち人間レベルの知能が社会のあらゆる領域を早ければ1年以内、遅くても3年以内に変革し始めることはほぼ間違いないと言っていいのではないでしょうか。
まだまだ上記議論は個人作業のため粗や抜け漏れなどあるかとは思いますが、その際はTwitterにてご指摘いただければ幸いです。
@bioshok3



トークをします-1-320x180.png)